
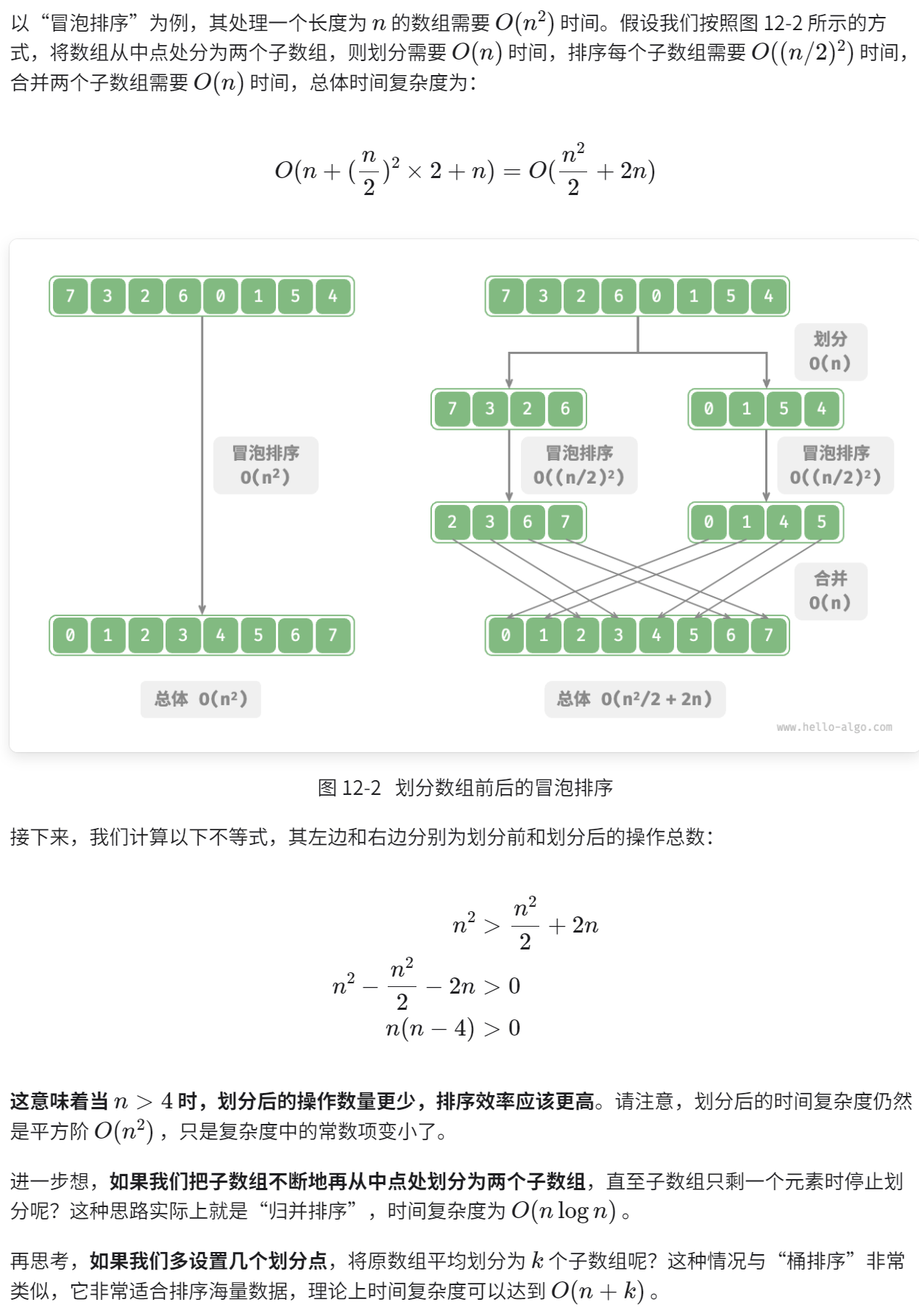
分治算法
一个问题是否适合使用分治解决,通常可以参考以下几个判断依据。
- 问题可以分解:原问题可以分解成规模更小、类似的子问题,以及能够以相同方式递归地进行划分。
- 子问题是独立的:子问题之间没有重叠,互不依赖,可以独立解决。
- 子问题的解可以合并:原问题的解通过合并子问题的解得来。
显然,归并排序满足以上三个判断依据。
- 问题可以分解:递归地将数组(原问题)划分为两个子数组(子问题)。
- 子问题是独立的:每个子数组都可以独立地进行排序(子问题可以独立进行求解)。
- 子问题的解可以合并:两个有序子数组(子问题的解)可以合并为一个有序数组(原问题的解)。
我们知道,分治生成的子问题是相互独立的,因此通常可以并行解决。也就是说,分治不仅可以降低算法的时间复杂度,还有利于操作系统的并行优化。
并行优化在多核或多处理器的环境中尤其有效,因为系统可以同时处理多个子问题,更加充分地利用计算资源,从而显著减少总体的运行时间。
分治搜索策略
搜索算法分为两大类。
- 暴力搜索:它通过遍历数据结构实现,时间复杂度为 𝑂(𝑛) 。
- 自适应搜索:它利用特有的数据组织形式或先验信息,时间复杂度可达到 𝑂(log𝑛) 甚至 𝑂(1) 。
实际上,时间复杂度为 𝑂(log𝑛) 的搜索算法通常是基于分治策略实现的,例如二分查找和树。 二分查找可以是基于递推(迭代)实现的。也可以是基于分治(递归)来实现的。
构建二叉树
原问题定义为从 preorder 和 inorder 构建二叉树,是一个典型的分治问题。
- 问题可以分解:从分治的角度切入,我们可以将原问题划分为两个子问题:构建左子树、构建右子树,加上一步操作:初始化根节点。而对于每棵子树(子问题),我们仍然可以复用以上划分方法,将其划分为更小的子树(子问题),直至达到最小子问题(空子树)时终止。
- 子问题是独立的:左子树和右子树是相互独立的,它们之间没有交集。在构建左子树时,我们只需关注中序遍历和前序遍历中与左子树对应的部分。右子树同理。
- 子问题的解可以合并:一旦得到了左子树和右子树(子问题的解),我们就可以将它们链接到根节点上,得到原问题的解。
def dfs(
preorder: list[int],
inorder_map: dict[int, int],
i: int,
l: int,
r: int,
) -> TreeNode | None:
"""构建二叉树:分治"""
# 子树区间为空时终止
if r - l < 0:
return None
# 初始化根节点
root = TreeNode(preorder[i])
# 查询 m ,从而划分左右子树
m = inorder_map[preorder[i]]
# 子问题:构建左子树
root.left = dfs(preorder, inorder_map, i + 1, l, m - 1)
# 子问题:构建右子树
root.right = dfs(preorder, inorder_map, i + 1 + m - l, m + 1, r)
# 返回根节点
return root
def build_tree(preorder: list[int], inorder: list[int]) -> TreeNode | None:
"""构建二叉树"""
# 初始化哈希表,存储 inorder 元素到索引的映射
inorder_map = {val: i for i, val in enumerate(inorder)}
root = dfs(preorder, inorder_map, 0, 0, len(inorder) - 1)
return root
设树的节点数量为 𝑛 ,初始化每一个节点(执行一个递归函数 dfs() )使用 𝑂(1) 时间。因此总体时间复杂度为 𝑂(𝑛) 。
哈希表存储 inorder 元素到索引的映射,空间复杂度为 𝑂(𝑛) 。在最差情况下,即二叉树退化为链表时,递归深度达到 𝑛 ,使用 𝑂(𝑛) 的栈帧空间。因此总体空间复杂度为 𝑂(𝑛)
def dfs(
preorder: list[int],
inorder_map: dict[int, int],
i: int,
l: int,
r: int,
) -> TreeNode | None:
在函数定义中, -> TreeNode | None: 是一个类型提示,用于指示该函数的返回类型。这种语法是 Python 3.5 引入的类型提示(type hinting)功能的一部分,旨在提高代码的可读性和可维护性。具体来说,这个类型提示表示:
- 该函数返回的类型要么是
TreeNode(树节点类型),要么是None。
类型提示并不会对代码的运行产生任何影响,它们只是用于静态类型检查工具(例如 mypy)或 IDE 提示,以帮助开发者理解代码的意图和结构。
所以,看到 ) -> TreeNode | None: 时,可以理解为:
- 函数参数列表结束后(即右括号
)后),箭头->表示返回类型。 TreeNode | None表示返回类型可以是TreeNode类型的对象,也可以是None。 这是为了让使用这个函数的人知道,他们调用这个函数时可以预期返回一个TreeNode对象或者None,这样可以帮助他们编写更健壮的代码,避免不必要的类型错误。
例如,结合你的代码片段:
def dfs(
preorder: list[int],
inorder_map: dict[int, int],
i: int,
l: int,
r: int,
) -> TreeNode | None:
"""构建二叉树:分治"""
...
这里的 ) -> TreeNode | None: 告诉我们 dfs 函数要么返回一个 TreeNode 类型的对象,要么返回 None。
在汉诺塔问题中,一个规模为 𝑛 的问题可以划分为两个规模为 𝑛−1 的子问题和一个规模为 1 的子问题。按顺序解决这三个子问题后,原问题随之得到解决。