
RULE激活函数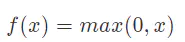
w.r.t. with respect to 常用于求导,或者满足一定条件之类的情况
MSE: 均方误差
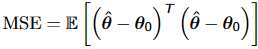
A ≜ B 定义A为B
凸偏好:

协方差cov(x)>0正相关<0负相关,协方差矩阵由方差和协方差组成,是一个对称矩阵
m个样本,$\Sigma=\frac{1}{m}XX_T$ **总体是除以m,样本是m-1,因为要保证无偏估计。在矩阵中用数学期望算更方便
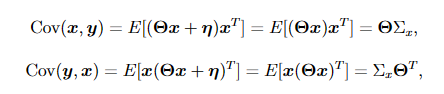
S(β) $\Rightarrow$ β的残差平方和
残差在数理统计中是指实际观察值与估计值(拟合值)之间的差,一般用 “ e ” 表示
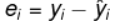
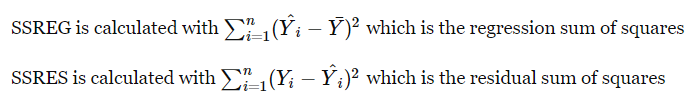
损失函数用来评价模型的预测值和真实值不一样的程度,有时候用残差的平方
i.i.d. 独立同分布
Gaussian process (GP) model (stochastic) 高斯过程 (GP) 模型(随机)
黑塞矩阵Hessian matrix:由多变量实值函数的所有二阶偏导数组成的方块矩阵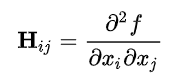
矩阵求导方法
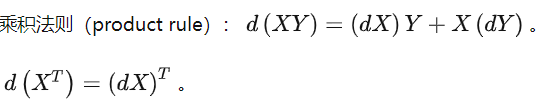
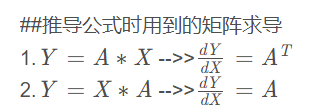
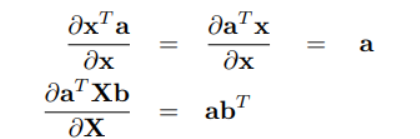 求导书
求导书
 $\nabla Ax = A$ 但是 $\nabla a^T x = a$ 注意是向量求导还是实值求导
$\nabla Ax = A$ 但是 $\nabla a^T x = a$ 注意是向量求导还是实值求导
极大似然估计(MLE)最大后验概率估计(MAP 频率学派认为世界是确定的。他们直接为事件本身建模,也就是说事件在多次重复实验中趋于一个稳定的值p,那么这个值就是该事件的概率。他们认为模型参数是个定值,希望通过类似解方程组的方式从数据中求得该未知数。这就是频率学派使用的参数估计方法-极大似然估计(MLE),这种方法往往在大数据量的情况下可以很好的还原模型的真实情况。 贝叶斯派认为世界是不确定的,因获取的信息不同而异。假设对世界先有一个预先的估计,然后通过获取的信息来不断调整之前的预估计。 他们不试图对事件本身进行建模,而是从旁观者的角度来说。因此对于同一个事件,不同的人掌握的先验不同的话,那么他们所认为的事件状态也会不同。 他们认为模型参数源自某种潜在分布,希望从数据中推知该分布。这就是贝叶斯派视角下用来估计参数的常用方法-最大后验概率估计(MAP),这种方法在先验假设比较靠谱的情况下效果显著,随着数据量的增加,先验假设对于模型参数的主导作用会逐渐削弱,相反真实的数据样例会大大占据有利地位。极端情况下,比如把先验假设去掉,或者假设先验满足均匀分布的话,那她和极大似然估计就如出一辙了。特点是一系列argmax/min以及其间灵活的转换
Fisher信息:可观察随机变量X携带的关于X的概率所依赖的未知参数θ的信息量
可以用来估计MLE方程的方差
一般情况下费雪信息是对数似然函数关于参数θ的二阶导数的负期望值
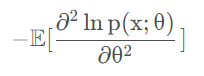
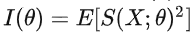
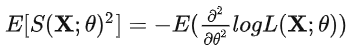 对于这样的一个log likelihood function,它越平而宽,就代表我们对于参数估计的能力越差,它高而窄,就代表我们对于参数估计的能力越好,也就是信息量越大。而这个log likelihood在参数真实值处的负二阶导数,就反应了这个log likelihood在顶点处的弯曲程度,弯曲程度越大,整个log likelihood的形状就越偏向于高而窄,也就代表掌握的信息越多。
对于这样的一个log likelihood function,它越平而宽,就代表我们对于参数估计的能力越差,它高而窄,就代表我们对于参数估计的能力越好,也就是信息量越大。而这个log likelihood在参数真实值处的负二阶导数,就反应了这个log likelihood在顶点处的弯曲程度,弯曲程度越大,整个log likelihood的形状就越偏向于高而窄,也就代表掌握的信息越多。
克拉美-罗下界(Cramer-Rao Lower Bound,CRLB) 不关心具体的估计方式,只是去反映:利用已有信息所能估计参数的最好效果。**任何无偏估计量的方差必定大于等于克拉美-罗界。 观测样本数越多,获取的信息越多,曲率越大,对数似然函数越”尖锐”。 是FIsher信息的倒数。
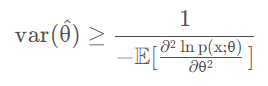
- Fisher信息值是所有无偏估计方案中方差最小的一个(最有效的一个),
- 是所有无偏估计量的方差的下界,
- 任何一个无偏估计量的方差都不会比它小,,也就是不会比它更好,
- 离它越近表示估计越好,越有效
- 另外,🍎信息越多,Fisher信息值越小,这个下界越低,表示估计越有效!
逻辑回归:
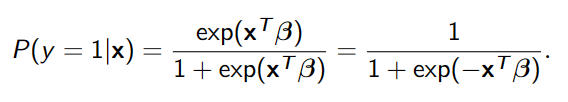
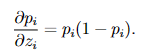
在机器学习中,超参数(hyperparameter)是在训练模型之前设置的配置参数,其值不能通过训练数据学习得到,而是需要手动选择。这与模型的参数不同,模型的参数是在训练过程中学习得到的,其值是由模型自动调整的。 超参数的选择可以对模型的性能和训练过程产生重要影响。一些常见的超参数包括:
- 学习率(Learning Rate): 在梯度下降等优化算法中,学习率控制了参数更新的步长。合适的学习率能够加速收敛,但过大的学习率可能导致算法发散,而过小的学习率则可能使得算法收敛速度过慢。
- 正则化参数: 正则化用于控制模型的复杂度,防止过拟合。超参数,如L1正则化和L2正则化的权重,用于平衡模型在训练数据上的拟合与泛化能力。
- 迭代次数(Epochs): 训练模型时的迭代次数。过少的迭代可能导致模型未能充分学习数据的特征,而过多的迭代可能导致过拟合。
- 批量大小(Batch Size): 在梯度下降中,每次更新模型参数时使用的样本数。合适的批量大小可以影响模型的收敛速度和内存使用。
- 隐藏层的神经元数量: 对于神经网络,隐藏层中神经元的数量是一个重要的超参数。不同的隐藏层结构可能对模型性能产生显著影响。
- 激活函数: 神经网络中每个神经元的激活函数是一个超参数,常见的包括ReLU、Sigmoid和Tanh等。
- 优化算法的参数: 对于梯度下降等优化算法,还有一些相关的超参数,如动量项、衰减率等。
前馈神经网络(feedforward neural network),也叫作多层感知机(MLP):
- 前馈网络定义了一个映射,目的是近似某个函数。
- 通常用许多不同函数复合在一起来表示。
- 该模型与一个有向无环图相关联,而图描述了函数是如何复合在一起的。
- 确定神经网络参数问题的一个简单方法是通过 最小化 最小二乘误差函数 。
- Softmax是一种激活函数,它可以将一个数值向量归一化为一个概率分布向量,且各个概率之和为1。Softmax可以用来作为神经网络的最后一层,用于多分类问题的输出。Softmax层常常和交叉熵损失函数一起结合使用。
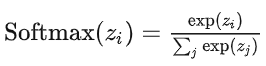
- 迭代算法: $W^ {\tau +1} = W^{\tau} -\eta \nabla E(W^ {\tau})$
- 交叉熵损失函数
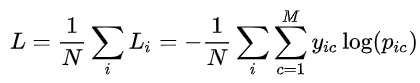
- 为了简化梯度下降的更新规则,常常在损失函数中引入1/2系数,这样在计算导数时,平方项的二次方会与1/2相互抵消,得到一个较为简洁的形式。
- 要求有对每个输入值期望得到的已知输出,来计算损失函数的梯度。主要监督学习。
- 主要由两个环节(激励传播、权重更新)反复循环迭代,直到网络的对输入的响应达到预定的目标范围为止。
- 在正向传播过程中,输入信息通过输入层经隐含层,逐层处理并传向输出层。如果在输出层得不到期望的输出值,则取输出与期望的误差的平方和作为目标函数,转入反向传播,逐层求出目标函数对各神经元权值的偏导数,构成目标函数对权值向量的梯量,作为修改权值的依据,网络的学习在权值修改过程中完成。误差达到所期望值时,网络学习结束。
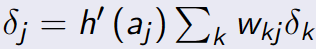
-
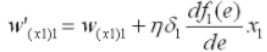
Methods for Regularization We introduce two different methods for regularization: Early Stopping Dropout
正则化
Regularization,中文翻译过来可以称为正则化,或者是规范化。在这里,规则化就是说给损失函数加上一些限制,通过这种规则去规范他们再接下来的循环迭代中,不要自我膨胀. Early Stopping:
- 一旦验证误差达到最小值就停止训练。
- 相对于独立数据(通常称为验证集)测量的误差通常首先显示出下降,然后随着网络开始过度拟合而增加。 Drop out:
- 我们在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征。
- 因为dropout程序导致两个神经元不一定每次都在一个dropout网络中出现。这样权值的更新不再依赖于有固定关系的隐含节点的共同作用,阻止了某些特征仅仅在其它特定特征下才有效果的情况 。
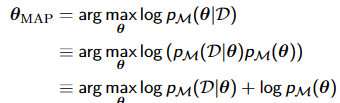 贝叶斯变量选择
P(x) 相当于是一个归一化项,整个公式就表示为:后验概率 正比于 先验概率 * 似然函数
贝叶斯变量选择
P(x) 相当于是一个归一化项,整个公式就表示为:后验概率 正比于 先验概率 * 似然函数
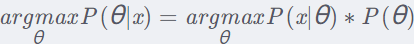
y 不是被估计的单个值,而是假设从一个正态分布中提取而来。 给定数据集D={X,y}, find out the posterior distribution (后验分布) p(w|y, X ) 给定一个新的输入 x,找出预测输出 p(y|x*, y, X ) 的后验分布
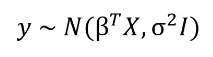 输出 y 是从一个由均值和方差两种特征刻画的正态(高斯)分布生成的。线性回归的均值是权重矩阵的转置和预测变量矩阵之积。方差是标准差 σ 的平方(乘以单位矩阵,因为这是模型的多维表示)。
贝叶斯线性回归的目的不是找到模型参数的单一「最佳」值,而是确定模型参数的后验分布。不仅响应变量是从概率分布中生成的,而且假设模型参数也来自于概率分布。模型参数的后验分布是以训练的输入和输出作为条件的。
输出 y 是从一个由均值和方差两种特征刻画的正态(高斯)分布生成的。线性回归的均值是权重矩阵的转置和预测变量矩阵之积。方差是标准差 σ 的平方(乘以单位矩阵,因为这是模型的多维表示)。
贝叶斯线性回归的目的不是找到模型参数的单一「最佳」值,而是确定模型参数的后验分布。不仅响应变量是从概率分布中生成的,而且假设模型参数也来自于概率分布。模型参数的后验分布是以训练的输入和输出作为条件的。
 后验吸收了似然性和先验的知识,并捕获了我们所知道的有关模型参数的所有信息。
权重的高斯先验:
后验吸收了似然性和先验的知识,并捕获了我们所知道的有关模型参数的所有信息。
权重的高斯先验:
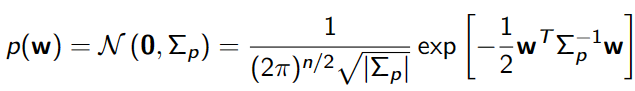
如上,贝叶斯线性回归下权重的分布是另一个高斯函数
高斯过程:在机器学习领域里,高斯过程是一种假设训练数据来自无限空间、并且各特征都符合高斯分布的有监督建模方式
- 高维高斯分布:
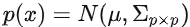
- 机器学习的训练过程目标就是学习该无限维高斯分布的子集——也是一个多元高斯分布的参数:均值向量和协方差矩阵
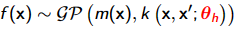
-

牛顿法迭代公式:
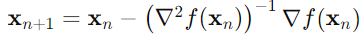
L1正则先验分布是Laplace分布,L2正则先验分布是Gaussian分布
laplace概率分布函数:
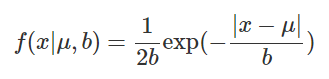 laplace先验概率:
laplace先验概率:
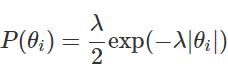
We introduce indicator variables $\gamma_j$ , j = 1, 2, …, p, whose value
indicates whether the j-th feature is “in” or “out” of our model
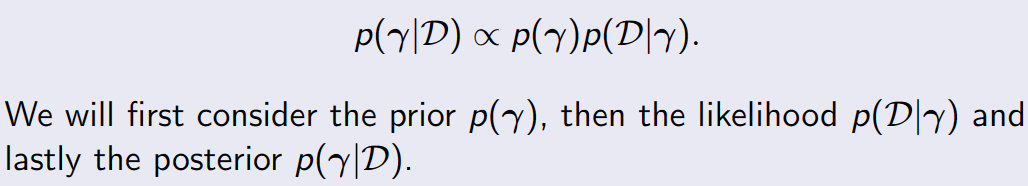
高斯过程:在机器学习领域里,高斯过程是一种假设训练数据来自无限空间、并且各特征都符合高斯分布的有监督建模方式
- 高斯分布(也叫做正态分布)是高斯过程的基础构件
- 高斯过程并不是说所有时刻对应的随机变量需要服从同一个高斯,只是服从的高斯分布的具体参数只跟时刻有关
-
GP的分布就是对于时间域上所有随机变量的联合分布
高维高斯分布:
多元高斯分布由 ==均值向量 μ== 和 ==协方差矩阵 Σ== 定义
==协方差矩阵==总是对称且半正定的
它在条件作用和边缘化情况下是封闭的;边缘化一个随机变量,只需把μ 和Σ 里对应的变量丢掉。
条件作用也是封闭的
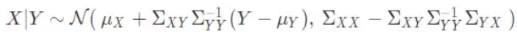 在高斯过程中,我们把每个测试点作为一个随机变量,多元高斯分布的维数和随机变量的数目一致。
在高斯过程中,我们把每个测试点作为一个随机变量,多元高斯分布的维数和随机变量的数目一致。
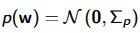
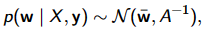
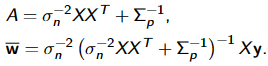
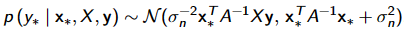
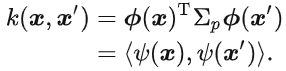 方程视角:
方程视角: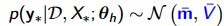 Z是测试输入
Z是测试输入
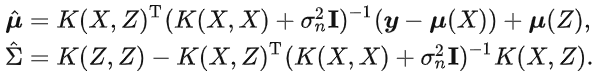
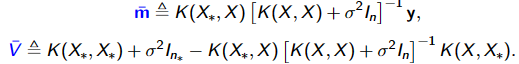 机器学习的训练过程目标就是学习该无限维高斯分布的子集——也是一个多元高斯分布的参数:均值向量和协方差矩阵
机器学习的训练过程目标就是学习该无限维高斯分布的子集——也是一个多元高斯分布的参数:均值向量和协方差矩阵
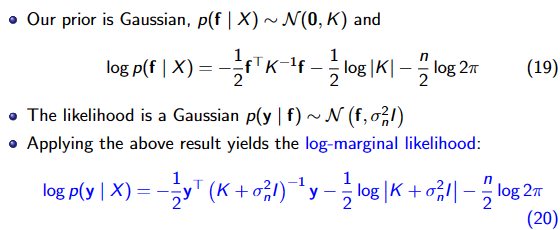
核函数:
- 如果原始空间是有限维,即属性数有限,那么一定存在一个高维特征空间使样本可分。
- 令∅(x)表示将x映射后的特征向量,于是,在特征空间中划分超平面所对应的模型可表示为
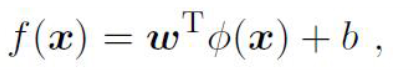
- 由于特征空间维数可能很高,甚至可能是无穷维,因此直接计算)$∅(x_i)^T∅(x_j)$通常是困难的。为了避开这个障碍,可以设想这样一个函数

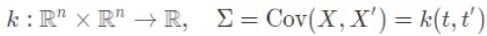
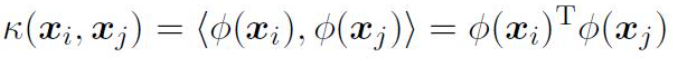
- 这被称为“核技巧”(kernel trick)
- 核方法、核技巧和核函数
- 核函数
- mapping function:
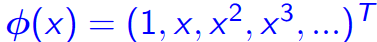
- maps a p-dimensional input vector into a new N-dimensional feature vector (often, N ≫ p)
- 生成高维特征空间的线性模型
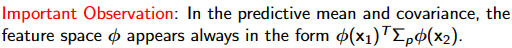
- We can rely on the kernel instead of the mapping function
- 采用等效核函数 $k(x, x′) = (≈)φ(x)^T φ(x)$ 的计算效率较高。
- 高斯过程模型直接用核函数
- 在核函数中,符号 $\theta_h$ 可能表示核函数的超参数,通常用于控制核函数的形状、复杂度或者特定的性质。
- 最常用的SE kernel:
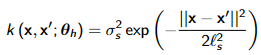
- 特点是对于输入空间中相近的样本,核函数的值趋于1,而对于远离的样本,核函数的值迅速趋近于0。这种特性使得 SE kernel 在捕捉数据之间的平滑关系和相似性方面非常有效。而且无限可微。
- $l$ 是控制核函数平滑度的长度尺度(length scale)超参数。
- 随着lengthscale的增大,GP的sample的波动变得越来越平缓(横向)
- $\sigma_s^2$ 是方差项,代表噪声水平或数据的不确定性水平。
-
$\sigma_s^2$ 导致不同振幅(竖向)
GPC:
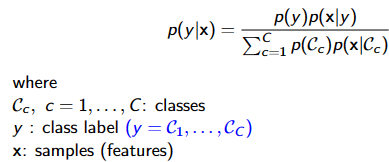
 Turning the output of a regression model into a class probability using a response function, mapping from (−∞, ∞) → [0, 1]
对于二项回归,似然函数:
Turning the output of a regression model into a class probability using a response function, mapping from (−∞, ∞) → [0, 1]
对于二项回归,似然函数:
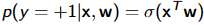 σ(z): mapping/squashing function
对于分类,后验没有简单的解析分布曲线
σ(z): mapping/squashing function
对于分类,后验没有简单的解析分布曲线
- compute the distribution of the latent function of a test point
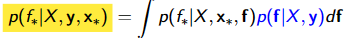
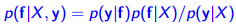
- Using this distribution over the latent f∗ to produce a probabilistic prediction
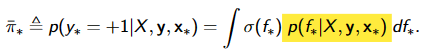 通常是非高斯的,积分困难
采用积分的解析近似或基于蒙特卡罗采样的解决方案
拉普拉斯近似法,期望传播法
拉普拉斯近似通过将后验分布近似为一个高斯分布,使得计算均值和方差等统计量更为方便。
通常是非高斯的,积分困难
采用积分的解析近似或基于蒙特卡罗采样的解决方案
拉普拉斯近似法,期望传播法
拉普拉斯近似通过将后验分布近似为一个高斯分布,使得计算均值和方差等统计量更为方便。
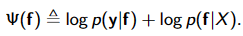 边际似然的拉普拉斯近似
边际似然的拉普拉斯近似
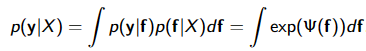
Zero-mean Laplace prior on parameters + MAP = ℓ1 regularization RSS(w) == w的残差平方和
朴素贝叶斯分类器采用了“属性条件独立性假设”(attribute conditional independence assumption):对已知类别,假设所有属性相互独立。 换言之,假设每个属性独立地对分类结果发生影响。
Parametric VS Non-parametric
verfitting No free lunch
**Linear Regression
\[y=\beta_0 + \beta_1\mathbf{x_1}+\beta_2\mathbf{x_2} +...+\epsilon\]least-squares(LS) estimator
\[\hat\beta s = arg\mathop{min}\limits_\beta S(\beta)\] \[\frac{\partial\mathbf{S}}{\partial\mathbf{\beta}}|_\hat\beta=-2\mathbf{x^T y}+2\mathbf{x^T x\hat\beta}\]Nonlinear Regression
- Parameter Estimation Performance
贝叶斯 核化 稀疏化 高斯过程回归
**支持向量(support vector): 距离超平面最近的这几个训练样本点
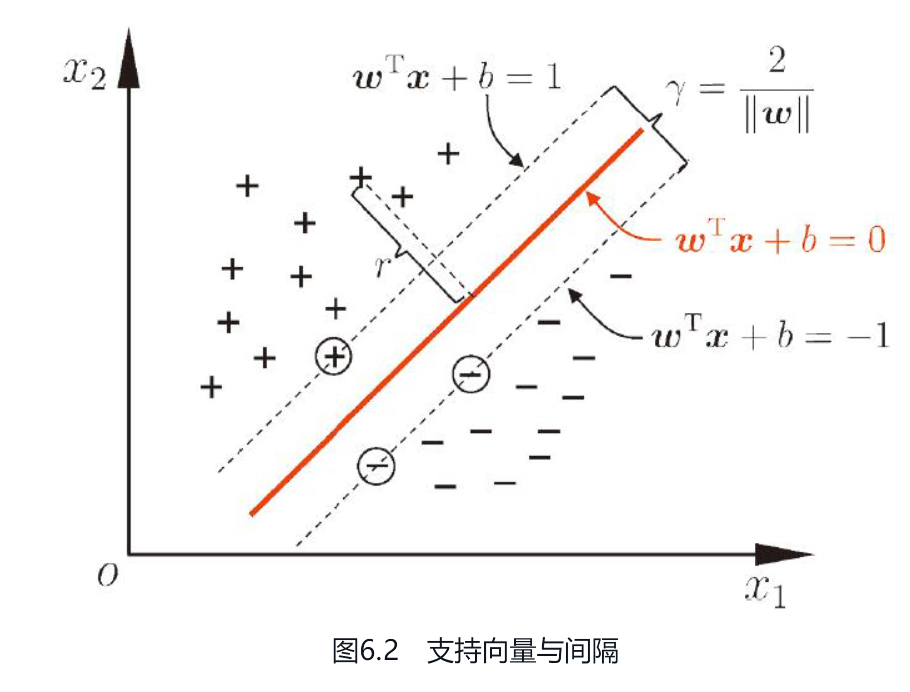
欲找到具有“最大间隔”(maximum margin)的划分超平面,也就是要找到能满足式(6.3)中约束的参数w和b,使得r最大。这就是支持向量机(SVM)的基本型。
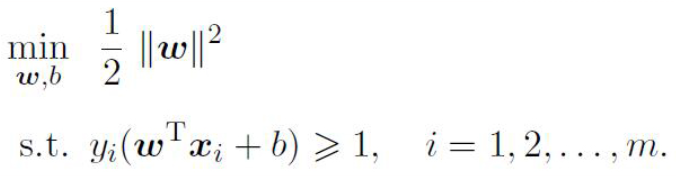

Specifically, we introduce the function $\phi$ (x) which maps a D-dimensional
input vector x into an N dimensional feature space.

«««< HEAD
在机器学习中,”hypotheses”(假设)通常指的是模型对数据的某种假设或猜测。在监督学习中,模型试图学习输入数据与输出标签之间的映射关系,这个映射关系就是模型的假设。例如,在线性回归中,假设是输入特征与输出标签之间存在线性关系。
- 对于一个监督学习问题,有一个包含输入和相应输出标签的训练数据集。模型通过学习这个数据集来形成一种关于输入和输出之间关系的假设。这个假设可以是一个简单的数学公式,比如线性方程,也可以是一个复杂的神经网络结构。
- 在无监督学习中,模型尝试从数据中发现一些潜在的结构或模式,也可以形成类似的假设,尽管在这种情况下,因为没有明确的输出标签,假设可能更加隐含或模糊。
VC Bound 是一种不确定性界限,它描述了学习算法在训练数据集上的性能与在未见过的数据上的性能之间的关系。具体来说,VC Bound 用于估计学习算法的泛化误差的上界。泛化误差是指算法在新样本上的性能,而不仅仅是在训练数据上的性能。
VC Bound 的基本思想是通过考察假设空间的复杂度来估计泛化误差的上限。假设空间是指模型可以表示的所有可能的函数。VC Bound 基于 VC 维,这是一种衡量假设空间复杂度的概念。VC 维可以理解为假设空间中可以被模型拟合的样本的最大数量。
VC Bound 的一般形式为:
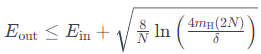 其中:
其中:
- $E_{out}$是泛化误差。
- $E_{in}$ 是训练误差。
- $N$ 是训练样本的数量。
- $m_H(N)$ 是假设空间的 VC 维。
-
$δ$ 是一个表示置信水平的参数。