
tips
- 当表达式中存在有符号类型和无符号类型时所有的操作数都自动转换为无符号类型。
- 在ARM的体系结构中,可以工作在三种不同的状态,一是ARM状态,二是Thumb状态及Thumb-2状态,三是调试状态。而ARM状态和Thumb状态可以直接通过某些指令直接切换,都是在运行程序,只不过指令长度不一样而已。
- ARM状态:arm处理器工作于32位指令的状态,所有指令均为32位;
- Thumb状态:arm执行16位指令的状态,即16位状态;
- volatile关键字的作用是防止变量被编译器优化,而优化是处于编译阶段,所以volatile关键字是在编译阶段起作用。
- extern在链接阶段,表示声明,可以置于变量或者函数前,以标示变量或者函数的定义在别的文件中,提示编译器遇到此变量和函数时在其他模块中寻找其定义。
- 关键字 volatile 是与 const 绝对对立的。它指示一个变量也许会被某种方式修改
- 实时操作系统是保证在一定时间限制内完成特定功能的操作系统。实时操作系统有硬实时和软实时之分,硬实时要求在规定的时间内必须完成操作,这是在操作系统设计时保证的;软实时则只要按照任务的优先级,尽可能快地完成操作即可。
- 用关键字 inline 放在函数定义(注意是定义而非声明)的前面即可将函数指定为内联函数,内联函数通常就是将它在程序中的每个调用点上“内联地”展开。
“static”->静态成员变量
在C++中,静态成员变量是属于类本身而不是类的实例的成员变量。与普通成员变量不同,静态成员变量只有一个副本,无论创建了多少个类的实例。这意味着,无论有多少个类的对象,它们都共享同一个静态成员变量。
静态成员变量通常用于表示与类相关的全局状态或属性,例如计数器、共享资源等。它们可以通过类名和作用域解析运算符 :: 来访问,而不需要创建类的实例。
下面是一个示例说明了静态成员变量的使用:
#include <iostream>
class MyClass {
public:
static int staticVar;
};
// 静态成员变量的初始化
int MyClass::staticVar = 0;
int main() {
MyClass obj1;
MyClass obj2;
// 使用类名和作用域解析运算符来访问静态成员变量
MyClass::staticVar = 5;
std::cout << "obj1.staticVar: " << obj1.staticVar << std::endl;
std::cout << "obj2.staticVar: " << obj2.staticVar << std::endl;
return 0;
}
在这个示例中,MyClass::staticVar 是一个静态成员变量。staticVar 的初始化在类外进行,表示它是属于类的,而不是类的实例。无论创建了多少个 MyClass 的对象,它们都共享同一个 staticVar。
“STL”->标准模板库
C++ STL(Standard Template Library,标准模板库)是 C++ 标准库的一部分,它提供了一组丰富的模板类和函数,用于实现常见的数据结构和算法。STL 的设计目标是提供高效、灵活和通用的数据结构和算法,以便开发者能够更轻松地编写高质量的代码。
STL 主要由以下几个组件组成:
-
容器(Containers):包括
std::vector、std::list、std::deque、std::set、std::map等,用于存储和管理数据。 -
迭代器(Iterators):提供了一种统一的访问容器元素的方式,使得算法可以适用于不同类型的容器。
-
算法(Algorithms):包括在容器上执行的各种操作,例如排序、查找、合并等。常见的算法包括
std::sort、std::find、std::transform等。 -
函数对象(Function Objects):也称为谓词(Predicate),是一种可调用对象,用于在算法中指定操作。常见的函数对象包括比较函数、哈希函数等。
-
迭代器适配器(Iterator Adapters):用于修改迭代器的行为,例如反向迭代器、插入迭代器等。
使用 STL,开发者可以编写高效且可复用的代码,而不必重复实现常见的数据结构和算法。STL 中的组件通常都是模板类或函数,因此可以轻松地适应不同的数据类型和需求。
例如,下面是一个使用 STL 的示例代码,演示了如何使用 std::vector 容器和 std::sort 算法来对一组整数进行排序:
#include <iostream>
#include <vector>
#include <algorithm>
int main() {
std::vector<int> nums = {4, 2, 6, 1, 5};
// 使用 std::sort 对整数向量进行排序
std::sort(nums.begin(), nums.end());
// 输出排序后的结果
std::cout << "Sorted numbers:";
for (int num : nums) {
std::cout << " " << num;
}
std::cout << std::endl;
return 0;
}
以上代码使用了 <vector>、<algorithm> 头文件,分别包含了 std::vector 容器和 std::sort 算法的声明。通过这些 STL 组件,可以方便地实现对整数向量的排序操作。
auto & :
这段代码 for (auto & c : magazine) 是一种 C++11 引入的语法,称为“范围基于范围的 for 循环”(range-based for loop)。它用于遍历容器中的每个元素,如数组、向量、字符串等。
逐步解释
auto:auto是 C++11 引入的自动类型推导关键字。在这里,编译器会自动推导出c的类型。因为magazine是一个std::string类型的对象,它其实是一个字符数组,所以c的类型被推导为char&(字符的引用类型)。
&(引用符号):&符号表示c是一个引用(reference)。通过引用操作,可以直接修改magazine中的字符,而不会复制每个字符的值。如果不使用&,c将是一个字符的副本(char类型),不能直接修改原始字符串中的字符。
c : magazine:- 这一部分表示
c将会迭代magazine字符串中的每个字符。循环体内部的操作会依次对magazine中的每一个字符执行。
- 这一部分表示
代码的作用
在这段代码中:
for (auto & c : magazine) {
cnt[c - 'a']++;
}
c是magazine字符串中的每个字符的引用。- 每次循环,
c都代表magazine中的一个字符。 cnt[c - 'a']++是基于当前字符c对应的位置在cnt数组中进行计数增加。
举个例子
假设 magazine = "abc", 则 for (auto & c : magazine) 的执行顺序如下:
- 第一次循环,
c = 'a',对cnt['a' - 'a']++进行操作,即cnt[0]++。 - 第二次循环,
c = 'b',对cnt['b' - 'a']++进行操作,即cnt[1]++。 - 第三次循环,
c = 'c',对cnt['c' - 'a']++进行操作,即cnt[2]++。
最终,cnt 数组的前三个元素分别是 1, 1, 1,表示 a、b、c 各出现了一次。
使用范围基于范围的 for 循环可以使代码更简洁和易读,尤其是在需要遍历整个容器时,非常便捷。
宏特性举例
问题
程序按64位编译,运行下列程序代码,打印输出结果是多少
#define CALC(x,y) (x*y)
int main(void) {
int i=3;
int calc;
char **a[5][6];
calc = CALC(i++, sizeof(a)+5);
printf("i=%d, calc=%d\n", i, calc);
return 0;
}
这个问题涉及到宏的展开、运算符的优先级和求值顺序。我们逐步分析代码,来确定最终的输出结果。
代码分析
**宏展开
首先,宏 CALC(x, y) 定义如下:
#define CALC(x,y) (x*y)
当 CALC(i++, sizeof(a)+5) 被使用时,宏会被展开为:
(i++ * (sizeof(a) + 5))
这意味着表达式被替换成了 i++ * (sizeof(a) + 5)。
**计算 sizeof(a)
数组 a 是一个 5x6 的二维数组,每个元素是一个指向 char* 的指针。由于系统按 64 位编译,因此指针的大小为 8 字节。
a[5][6]中有5 * 6 = 30个元素。- 每个元素
char**占 8 字节。
所以 sizeof(a) 的大小是:
sizeof(a) = 30 * 8 = 240 字节
因此,sizeof(a) + 5 的值为:
sizeof(a) + 5 = 240 + 5 = 245
**表达式求值
我们现在来分析表达式 i++ * 245:
i++的值在此表达式中使用时是3,但之后i的值会被增加到4。- 因此,表达式的结果是
3 * 245,即735。
**最后,变量的值
i的最终值为4(因为i++导致了i自增)。calc的值为735。
输出结果
最终,程序将打印:
i=4, calc=735
所以,程序的输出结果是 i=4, calc=735。
大小端问题
A=0x12345678存入地址1000H~10003H中,
小端模式:1000H=78 1001H=56 1002H=34 1003H=12
大端模式:1000H=12 1001H=34 1002H=56 1003H=78
内存对齐原则
内存对齐(Memory Alignment)是指在计算机系统中,数据在内存中的存储地址需要按照特定的对齐规则进行排列,以提高内存访问效率。内存对齐原则在不同的硬件架构和编译器中可能有所不同,但其目标都是为了优化数据访问的速度和效率。
内存对齐的基本原则
- 基本对齐原则:
- 对齐要求: 数据类型的对齐要求决定了数据存储的起始地址必须是数据类型大小的整数倍。例如,4 字节的
int类型的对齐要求是 4 字节,那么它的存储地址必须是 4 的倍数。 - 字节对齐: 一般来说,1 字节的
char类型可以存储在任意地址,而 2 字节的short类型通常需要存储在 2 字节对齐的地址(如 0x0002、0x0004 等),4 字节的int类型需要存储在 4 字节对齐的地址。
- 对齐要求: 数据类型的对齐要求决定了数据存储的起始地址必须是数据类型大小的整数倍。例如,4 字节的
- 数据结构的对齐:
- 当数据结构(如结构体)中包含多个成员时,每个成员都按照自己的对齐要求排列。编译器可能会在成员之间插入填充字节(padding)以确保对齐。
- 结构体的整体对齐要求通常是其中最大对齐要求成员的对齐要求。
- 对齐的优点:
- 提高内存访问速度: 现代处理器通常在内存对齐的情况下能够更快地访问数据。未对齐的数据访问可能会导致处理器需要进行额外的内存访问操作,从而降低性能。
- 简化硬件设计: 对齐的内存访问简化了硬件设计,尤其是缓存系统的设计。它减少了跨越多个缓存行的数据访问,从而提高了缓存命中率。
示例
考虑以下结构体:
struct MyStruct {
char a; // 1 字节
int b; // 4 字节
short c; // 2 字节
};
在 32 位系统上,这个结构体的对齐和内存布局可能如下:
a(char)占 1 字节,起始地址可以是任意地址。b(int)需要 4 字节对齐,所以b通常会从偏移量 4 开始,而在a和b之间会插入 3 字节的填充字节以满足b的对齐要求。c(short)需要 2 字节对齐,所以c从偏移量 8 开始,结构体整体大小为 10 字节(1 + 3 填充字节 + 4 + 2)。
然而,编译器通常会为结构体的总大小插入填充字节,使其对齐到最大的对齐要求(在本例中为 4 字节)。所以 MyStruct 的最终大小可能是 12 字节,而不是 10 字节。
常见的内存对齐方式
- 字节对齐(1 字节):
- 适用于
char类型或无对齐要求的数据。
- 适用于
- 2 字节对齐:
- 适用于
short类型等需要 2 字节对齐的数据。
- 适用于
- 4 字节对齐:
- 常见于
int、float类型,通常用于 32 位系统。
- 常见于
- 8 字节对齐:
- 常见于
double类型或指针,尤其是在 64 位系统上。
- 常见于
总结
每个特定平台上的编译器都有自己的默认“对齐系数”(32位机一般为4,64位机一般为8)。我们可以通过预编译命令#pragma pack(k),k=1,2,4,8,16来改变这个系数,其中k就是需要指定的“对齐系数”。
只需牢记: 第一个数据成员放在offset为0的地方,对齐按照对齐系数和自身占用字节数中,二者比较小的那个进行对齐; 在数据成员完成各自对齐以后,struct或者union本身也要进行对齐,对齐将按照对齐系数和struct或者union中最大数据成员长度中比较小的那个进行;
内存对齐原则是为了优化内存访问速度而设计的规则,确保数据类型的存储地址满足一定的对齐要求。合理的内存对齐可以提高处理器的访问效率,减少访问未对齐数据的开销。在编写涉及内存操作的低级代码或与硬件接口的程序时,理解和遵循内存对齐原则非常重要。
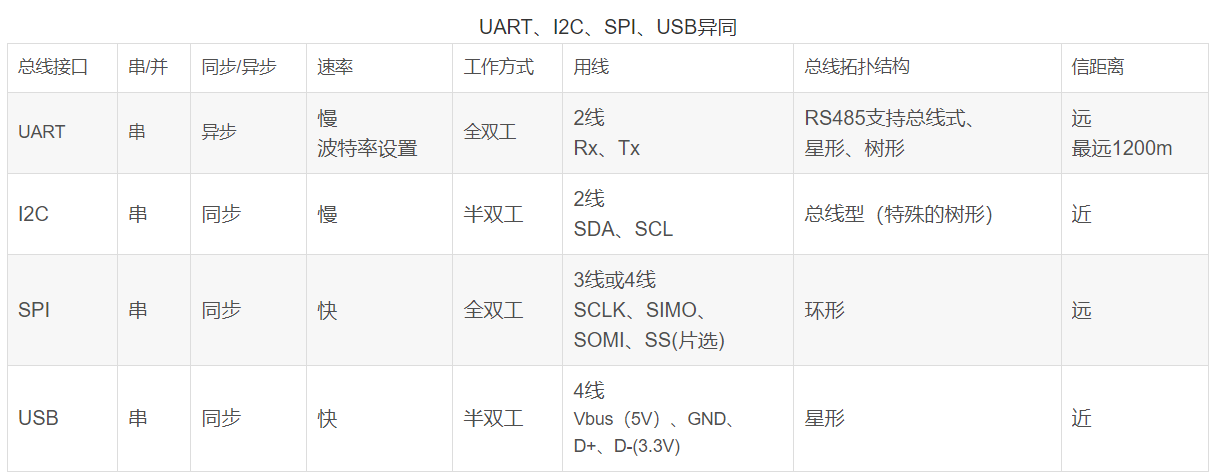
总线接口
- UART:通用异步串行口,速率不快,可全双工,结构上一般由波特率产生器、UART发送器、UART接收器组成,硬件上两线,一收一发;
- I2C:双向、两线、串行、多主控接口标准。速率不快,半双工,同步接口,具有总线仲裁机制,非常适合器件间近距离经常性数据通信,可实现设备组网;
- SPI:高速同步串行口,高速,可全双工,收发独立,同步接口,可实现多个SPI设备互联,硬件3~4线;
- USB 通用串行总线,高速,半双工,由主机、hub、设备组成。设备可以与下级hub相连构成星型结构。
linux相关
4、Linux的用户态与内核态的转换方法。(选择题) 解答:Linux下内核空间与用户空间进行通信的方式主要有syscall(system call)、procfs、ioctl和netlink等。
syscall:一般情况下,用户进程是不能访问内核的。它既不能访问内核所在的内存空间,也不能调用内核中的函数。Linux内核中设置了一组用于实现各种系统功能的子程序,用户可以通过调用他们访问linux内核的数据和函数,这些系统调用接口(SCI)称为系统调用; procfs:是一种特殊的伪文件系统 ,是Linux内核信息的抽象文件接口,大量内核中的信息以及可调参数都被作为常规文件映射到一个目录树中,这样我们就可以简单直接的通过echo或cat这样的文件操作命令对系统信息进行查取; netlink:用户态应用使用标准的 socket API 就可以使用 netlink 提供的强大功能; ioctl:函数是文件结构中的一个属性分量,就是说如果你的驱动程序提供了对ioctl的支持,用户就可以在用户程序中使用ioctl函数控制设备的I/O通道。
5、linux目录结构,选项是/usr、/tmp、/etc目录的作用。(选择题) 解答:linux目录图:
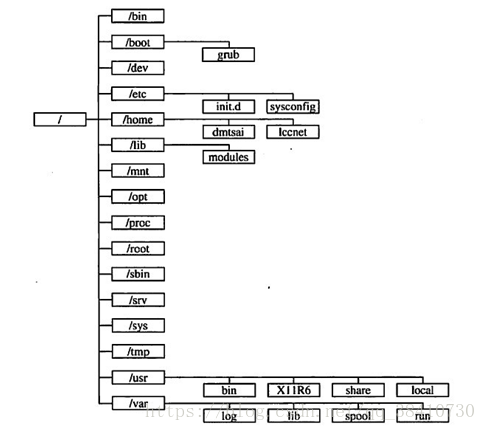
/usr:不是user的缩写,其实usr是Unix Software Resource的缩写, 也就是Unix操作系统软件资源所放置的目录,而不是用户的数据啦。这点要注意。 FHS建议所有软件开发者,应该将他们的数据合理的分别放置到这个目录下的次目录,而不要自行建立该软件自己独立的目录; /tmp:这是让一般使用者或者是正在执行的程序暂时放置档案的地方。这个目录是任何人都能够存取的,所以你需要定期的清理一下。当然,重要资料不可放置在此目录啊。 因为FHS甚至建议在开机时,应该要将/tmp下的资料都删除; /etc:系统主要的设定档几乎都放置在这个目录内,例如人员的帐号密码档、各种服务的启始档等等。 一般来说,这个目录下的各档案属性是可以让一般使用者查阅的,但是只有root有权力修改。 FHS建议不要放置可执行档(binary)在这个目录中。 比较重要的档案有:/etc/inittab, /etc/init.d/, /etc/modprobe.conf, /etc/X11/, /etc/fstab, /etc/sysconfig/等等。
const与指针
const int a;
int const a;
const int *a;
int * const a;
const int * const a;
int const * const a;
前两个的作用是一样,a是一个常整型数; 第三个意味着a是一个指向常整型数的指针(也就是,整型数是不可修改的,但指针可以); 第四个意思a是一个指向整型 数的常指针(也就是说,指针指向的整型数是可以修改的,但指针是不可修改的); 最后两个意味着a是一个指向常整型数的常指针(也就是说,指针指向的整型数 是不可修改的,同时指针也是不可修改的)。
C的各种变量存取
堆:堆允许程序在运行时动态地申请某个大小的内存。一般由程序员分配释放; 栈:由编译器自动分配释放,存放函数的参数值,局部变量等值; 静态存储区:一定会存在且不会消失,这样的数据包括常量、常变量(const 变量)、静态变量、全局变量等; 常量存储区:常量占用内存,只读状态,决不可修改,常量字符串就是放在这里的。
中段处理
所谓中断,就是指CPU在正常执行程序的时候,由于内部/外部事件的触发、或由程序预先设定,而引起CPU暂时中止当前正在执行的程序,保存被执行程序相关信息到栈中,转而去执行为内部/外部事件、或由程序预先设定的事件的中断服务子程序,待执行完中断服务子程序后,CPU再获取被保存在栈中被中断的程序的信息,继续执行被中断的程序,这一过程叫做中断。
了解了中断的定义,再来看一下中断的几个概念:
中断向量:中断服务程序的入口地址; 中断向量表:把系统中所有的中断类型码及其对应的中断向量按一定的规律存放在一个区域内,这个存储区域就叫做中断向量表; 中断源:软中断/内中断、外中断/硬件中断、异常等。 处理器在中断处理的过程中,一般分为以下几个步骤:
请求中断→中断响应→保护现场→中断服务→恢复现场→中断返回。
详细地讲解:
请求中断:当某一中断源需要CPU为其进行中断服务时,就输出中断请求信号,使中断控制系统的中断请求触发器置位,向CPU请求中断。系统要求中断请求信号一直保持到CPU对其进行中断响应为止; 中断响应:CPU对系统内部中断源提出的中断请求必须响应,而且自动取得中断服务子程序的入口地址,执行中断服务子程序。对于外部中断,CPU在执行当前指令的最后一个时钟周期去查询INTR引脚,若查询到中断请求信号有效,同时在系统开中断(即IF=1)的情况下,CPU向发出中断请求的外设回送一个低电平有效的中断应答信号,作为对中断请求INTR的应答,系统自动进入中断响应周期; 保护现场:主程序和中断服务子程序都要使用CPU内部寄存器等资源,为使中断处理程序不破坏主程序中寄存器的内容,应先将断点处各寄存器的内容(主要是当前IP(将要执行的下一条地址)和CS值(代码段地址))压入堆栈保护起来,再进入的中断处理。现场保护是由用户使用PUSH指令来实现的; 中断服务:中断服务是执行中断的主体部分,不同的中断请求,有各自不同的中断服务内容,需要根据中断源所要完成的功能,事先编写相应的中断服务子程序存入内存,等待中断请求响应后调用执行; 恢复现场:当中断处理完毕后,用户通过POP指令将保存在堆栈中的各个寄存器的内容弹出,即恢复主程序断点处寄存器的原值。 中断返回:在中断服务子程序的最后要安排一条中断返回指令IRET(interrupt return),执行该指令,系统自动将堆栈内保存的 IP(将要执行的下一条地址)和CS值(代码段地址)弹出,从而恢复主程序断点处的地址值,同时还自动恢复标志寄存器FR或EFR的内容,使CPU转到被中断的程序中继续执行。 而中断嵌套是指中断系统正在执行一个中断服务时,有另一个优先级更高的中断提出中断请求,这时会暂时终止当前正在执行的级别较低的中断源的服务程序,去处理级别更高的中断源,待处理完毕,再返回到被中断了的中断服务程序继续执行,这个过程就是中断嵌套。
最后,补充几个知识点:
CS:IP两个寄存器:指示了 CPU 当前将要读取的指令的地址,其中CS为代码段寄存器,而IP为指令指针寄存器 。可以简单地认为,CS段地址,IP是偏移地址。 RET:也可以叫做近返回,即段内返回。处理器从堆栈中弹出IP或者EIP,然后根据当前的CS:IP跳转到新的执行地址。如果之前压栈的还有其余的参数,则这些参数也会被弹出; RETF:也叫远返回,从一个段返回到另一个段。先弹出堆栈中的IP/EIP,然后弹出CS,有之前压栈的参数也会弹出。(近跳转与远跳转的区别就在于CS是否压栈); IRET:用于从中断返回,会弹出IP/EIP,然后CS,以及一些标志。然后从CS:IP执行。